For the past few years, Python has consistently ranked as one of the popular programming languages, along with JavaScript and SQL. Statistics show that jobs related to Python projects are increasing year by year. Glassdoor currently lists more than 90,000 jobs available, while Indeed has about 71,000 current openings.
The credit for increased demand for Python goes to its design philosophy (which focuses on code readability) and its language constructs (which aims to help coders write clear, logical code).
Plus, some empirical studies have shown that scripting languages like Python are more productive than traditional languages like C and Java, especially in projects that involve search and string manipulation.
But why is Python so much popular among data scientists? This is because Python has various specialized libraries for Math, data mining, data exploration, visualization, and other data science projects.
The official repository for third-party Python tools, known as the Python Package Index (PyPI), contains more than 345,000 packages with a broad range of functionality, from text/image processing and data analytics to machine learning and automation.
Below, we have gathered some of the most useful Python libraries for data science that can make your workflow more productive and enhance your developer profile.
Table of Contents
9. Scrapy

Best for – Extracting data from websites
Initially developed for web scraping, Scrapy is now used to extract data through APIs or as a web crawler. The framework architecture is built around self-contained crawlers called ‘spiders.’
It is packed with some really helpful features, like rotating proxies auto-throttle, that allow you to scrape virtually undetected across the Internet. It also has a web-crawling shell, which you can utilize to test your assumptions on a website’s behavior.
Scrapy’s robust encoding support and auto-detection make it easier to deal with non-standard and broken encoding declarations. Moreover, it has a wide range of built-in extensions and middleware for handling cookies, sessions, HTTP features like authentication and caching, crawl depth restriction, and user-agent spoofing.
8. PyCaret
![]()
Best for – Static and interactive visualization
PyCaret is an open-source, low-code machine learning library that speeds up your coding and makes you more productive. It can be used to replace hundreds of lines of code with few lines only.
The main objective of this library is to automate crucial steps for evaluating and comparing machine learning models for classification and regression. For example, it can automate the steps to
- Define the data transforms
- Evaluate and compare standard models
- Turn model hyperparameters
PyCaret has more than 60 plots, which can be used to quickly analyze model performance and outcomes without the need to write large scripts.
Overall, the library is ideal for data scientists who want to improve their workflow or who prefer a low code machine learning solution. It could also be useful for researchers and consultants involved in developing Proof of Concept projects.
7. SQLAlchemy

Best for – Developing and managing high-performance databases
SQLAlchemy is an open-source SQL toolkit and Object Relational Mapper (ORM) that gives you the flexibility and complete control of SQL. Using ORM, you can develop object model and database schema in a cleanly decoupled way from the beginning.
SQLAlchemy takes care of all redundant tasks, enabling you to focus on major things like how to construct and organize SQL. It considers the database as a relational algebra engine, not just a set of tables. Rows can be selected from tables, joins, and other select statements.
The goal of the library is to change the way you think about databases and SQL. Unlike other tools, SQLAlchemy never gets in the way of database and application architecture. It does not generate schemas or rely on any kind of naming convention.
Plus, SQLAlchemy supports as many databases and architectural designs as reasonably possible. It is extensively used by many Internet companies, including Reddit, Survey Monkey, Dropbox, and Yelp.
6. Keras
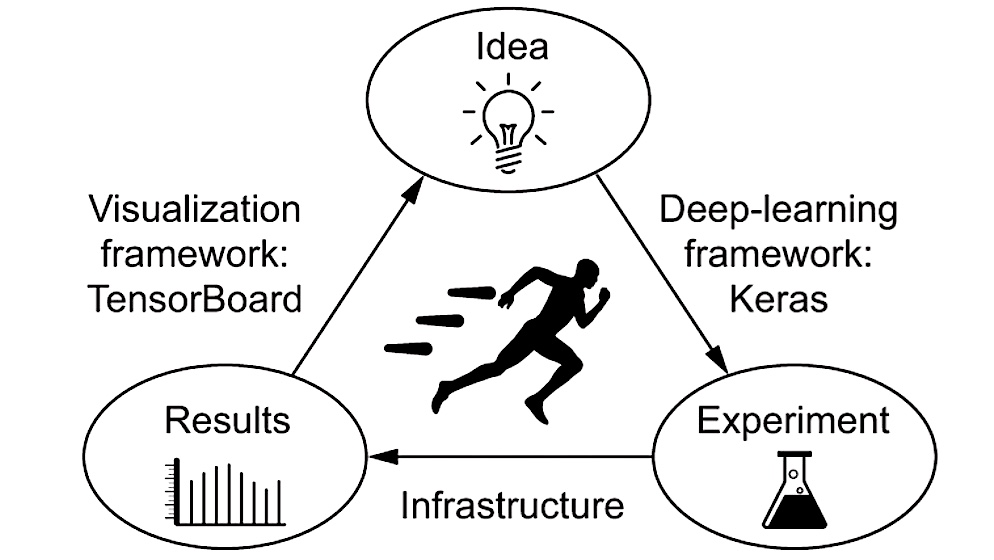
Best for – Prototyping and running new experiments
Keras is a part of the TensorFlow ecosystem. It is designed to be fast, modular, and easy to use. Since it makes it easier to run prototypes, you can try more ideas in less time.
This open-source library covers all phases of the machine learning workflow, from data management to hyperparameter training to deployment solutions. It also supports convolutional and recurrent neural networks and conventional utility layers such as dropout, batch normalization, and pooling.
With Keras, you can productize deep models on the web, smartphone (Android and iOS devices), and Java Virtual Machine. The library seamlessly runs on CPUs and can be scaled to large clusters of GPUs.
Because it enables fast experimentation and is appropriate for building essentially any deep learning model, it is used by many scientific organizations across the world, including NASA, CERN, and NIH.
5. Pandas

Best for – Data manipulation and analysis
Pandas is a powerful yet easy-to-use Python package that provides numerous data structures and operations for manipulating numerical data and time series. It includes functions for reading and writing data between in-memory data structures and different formats like MS Excel, CSV, and the fast HDF5 format.
Not only does it help you analyze big data and make conclusions based on statistical theories, but it also cleans messy data sets and makes them readable and relevant.
The library supports intelligent label-based slicing, integrated handling of missing data, and high-performance merging and joining of datasets.
Because of these features, it is used in various academic and commercial domains, ranging from finance and statistics to web analytics and advertising.
4. Matplotlib
 Matplotlib 3D plots
Matplotlib 3D plots
Best for – Static and interactive visualization
Matplotlib is a full-featured library for making static, animated, and interactive visualizations in Python. It allows you to create high-quality graphs in various formats and interactive environments across platforms.
The library can be used in Python scripts, web applications servers, the Python and IPython shell, and many other graphical user interface toolkits.
There are numerous toolkits available on the Internet (for free), which further extend the functionality of Matplotlib. While some can be downloaded separately, some come with the Matplotlib source code. Both have external dependencies. One such popular toolkit is Cartopy, which features object-oriented map projection definitions and image transformation capabilities.
Excel tools make it easy to exchange data with MS Excel. GTK tools provide an interface to the GTK library. Dozens of similar tools are available to make your workflow more efficient.
3. NumPy

Best for – Performing mathematical operations on large arrays
NumPy, short for Numerical Python, is the fundamental package for scientific computing in Python. It contains multidimensional array objects and a large set of routines for processing those arrays.
The library supports a broad range of operating systems and hardware, and works well with distributed GPU. Its high-level syntax makes it accessible and productive for both beginners and experienced developers.
NumPy is created to bring the computational power of Fortran and C languages to Python. It provides an array object that is up to 50 times faster than conventional Python lists. Plus, it is configured to work with the latest CPU architectures.
Unlike MATLAB that boasts several additional toolboxes (such as Simulink), NumPy is intrinsically integrated with Python. Both allow developers to write efficient code as long as operations work on matrices or arrays (instead of scalars).
Did you know that NumPy’s array data processing system was used by data scientists to obtain the first-ever image of a black hole? It has also helped researchers answer complex questions and discover new horizons in our understanding of the universe.
2. SciPy
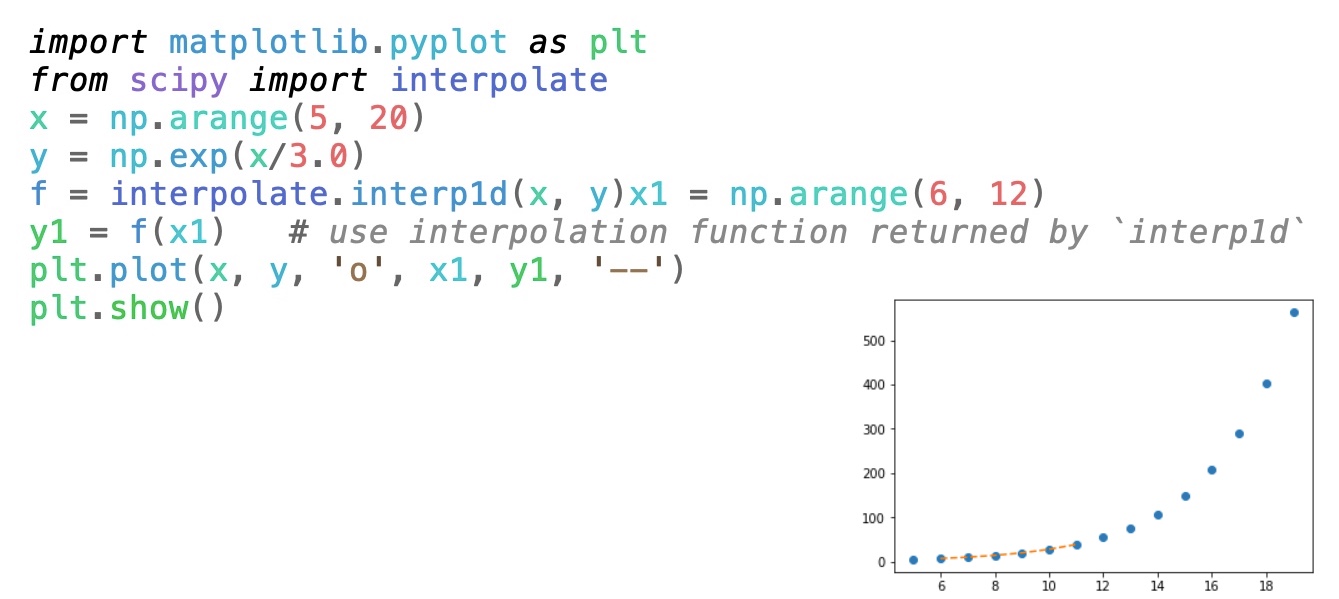
Best for – Statistics, optimization, and signal processing
SciPy is a free and open-source library for technical and scientific computing. Released in 2001, it has become a de-facto standard for utilizing scientific algorithms in Python, with over 700 unique code contributors, thousands of dependent packages, over 110,000 dependent repositories, and millions of downloads every year.
The library provides algorithms for integration, interpolation, differential equations, algebraic equations, statistics, optimizations, and various other classes of problems. It wraps high-optimized implementations written in low-level languages such as C++, C, and Fortran.
SciPy also offers specialized data structures like k-dimensional trees and sparse matrices. It contains a full-featured version of the linear algebra module as well as many other mathematical algorithms to resolve linear algebra, Fourier transforms, and perform basic operations like sorting, indexing, and visualization.
SciPy is itself the foundation upon which more-detailed libraries, including scikit-image and scikit-learn, are built.
1. Scikit-learn

Best for – Predictive data analysis
Scikit-learn is an open-source, machine learning library for Python that provides functionality supporting supervised and unsupervised learning. It includes tools for model development, selection, evaluation, and various other utilities for data pre-processing.
Scikit-learn is built to interoperate with NumPy, SciPy, and Matplotlib. While some of its core algorithms are written in Cython to enhance performance, the majority of the part is written in Python and it utilizes NumPy for high-performance linear algebra and array operations.
The library features tons of classification, regression, clustering, dimensionality reduction, model selection, and preprocessing algorithms, including nearest neighbors, random forest, spectral clustering, k-Means, gradient boosting, random forests, non-negative matrix factorization, feature selection, and feature extraction.
It can make your workflow more efficient, especially if your project revolves around image recognition, spam detection, grouping experiment outcomes, stock price analysis, customer segmentation, or grouping experiment outcomes.
Read: 35+ Tools to Minify Code (JavaScript, CSS & HTML)
Other Useful Libraries
10. Beautiful Soup
Best for – Pulling data out of HTML and XML files
Beautiful Soup is used for extracting HTML and XML data, including documents with malformed markup such as non-closed tags. The library is powerful enough to parse anything you want. For example, you can instruct it to “file all the links of class internetLink”, “find links containing author/varun“, or “list all tables that contain at least two hyperlinks”.
The library generates a parse tree for parsed webpages and automatically transforms the incoming data to Unicode and outgoing data to UTF-8. You don’t have to worry about the encoding.
Since the library includes popular Python parsers like html5lib and lxml, you can test various parsing techniques or trade speed for flexibility.
Note: Before scraping any site, look for the privacy policy or terms and conditions page. If the website has no explicit rules about scraping, then it becomes more of a judgment call.
11. Plotly
Best for – Creating interactive web-based visualizations
Plotly.py is an open-source, interactive graphing library for Python. It supports more than 40 unique chart types covering a broad range of financial, statistical, scientific, geographic, and three-dimensional use cases.
You can use this library to create, view, and distribute visualizations without registering to any service, creating an account, or obtaining any token. However, you will need to have a Mapbox token to view tile maps.
12. XGBoost
Best for – Training machine learning models
XGBoost stands for eXtreme Gradient Boosting. It is designed to increase computational speed and optimize model performance.
Unlike other machine learning tools that train all models independently, XGBoost uses sequential ensemble methods in which each new model is trained to correct the errors made by the previous ones.
The first model is built on training datasets, the second model improves the first model, the third model improves the second, the fourth improves the third, and so on. Models are added sequentially until there is no room for improvement.
This iterative approach is better than training individual models in isolation, where all of the models might simply end up making the same error.
The library contains parameters for regularisation and cross-validation. Plus, it can harness the power of multiple CPUs and GPUs across the network of computers, making it feasible to train models on massive datasets.
Read: 16 Useful Machine Learning Cheat Sheets
13. Seaborn
Best for – Making statistical graphics
Seaborn is an open-source library based on matplotlib. It provides a detailed interface for creating interactive statistical graphics.
The library gives you numerous options for plot style and color defaults, defines high-level functions for conventional statistical plot types, and closely integrates to the data structures from pandas.
Since Seaborn allows you to create complete graphics from a single function call with minimal arguments, you can easily perform rapid prototyping and exploratory data analysis. It also makes it easy to create polished, publication-quality figures.
Overall, the library is very useful for data scientists, business analysts, financial analysts, and other professionals who work with data.
14. Natural Language Toolkit
Best for – Developing programs to work with human language data
Natural Language Toolkit (NLTK) is a suite of open-source Python modules, datasets, and tutorials supporting R&D in Natural Language Processing (NLP). It provides numerous text processing libraries for classification, tokenization, parsing, tagging, and semantic reasoning.
NLTK’s primary goal is to support research and teaching in NLP or closely related fields like information retrieval, artificial intelligence, cognitive science, and empirical linguistics.
It is widely used as a platform for prototyping and developing research systems. Also, over 30 universities in the United States use NTLK as a teaching tool.
Read: 20+ Helpful Python Cheat Sheet
Frequently Asked Questions
What is the most famous Python tool for machine learning?
TensorFlow is one of the most popular end-to-end open-source platforms for machine learning (ML). It is packed with a flexible ecosystem of libraries, tools, and community resources that allow you to push the state-of-the-art in ML and easily create and deploy ML-powered software.
Although TensorFlow is written in Python, C++, and CUDA, it can be used in a broad range of programming languages, especially in Python, C++, Java, and JavaScript. This is why it has countless applications in many different sectors.
Is python enough for data science?
No! While Python is more than enough as a programming language for machine learning projects, it alone cannot get you a job as a data scientist in the corporate world.
You will need to have other skills as well (such as SQL, R programming language, exploratory data analysis, data visualization, machine learning algorithms, and statistics) in order to become a full-fledged data scientist.
Python is just a piece of the puzzle for tech giants to process massive volumes of data.
Read: 14 Best Programming Software For Writing Code
How much do data scientists make?
According to the US Bureau of Labor Statistics, the mean annual wage of data scientists is $103,930. The highest-paying companies in the US are Selby Jennings,
Apple, Airbnb, Genentech, and Twitter.
And since the supply of data professionals is still below the demand, salaries for these positions remain high, especially for people who have an advanced degree and years of experience in data science or a related field. Usually, starting salaries range between $75,000 and $240,000 per annum.