In Information Technology, systems design involves determining the architecture, interfaces, modules, and data to fulfill specific requirements. It’s a crucial process for improving product/service development efficiencies and enabling a great user experience.
Let’s say you have an application that serves millions of users every day. On the server side, you need excellent engineering to handle such a large volume of requests. Server requests must never fail, even if there is a database issue or a hardware failure.
However, if the backend or frontend is not designed correctly, a simple mistake could shut down the entire application — everything from the server to the computer-wide network. One of the major sources of such errors is the Single Point Of Failure (SPOF).
In this overview article, we explain why SPOF is the worst problem for IT professionals, its common causes, and how to mitigate such failures. Let’s start with a basic question.
Table of Contents
What is a Single Point Of Failure?
Definition: A single point of failure is any part of a system that causes the entire system to stop operating if it fails. In simple terms, if one thing breaks, everything goes down.
SPOFs arise from faulty designs and poor implementation practices. They are undesirable in any system, be it a software application, hardware module, manufacturing system, or business practice.
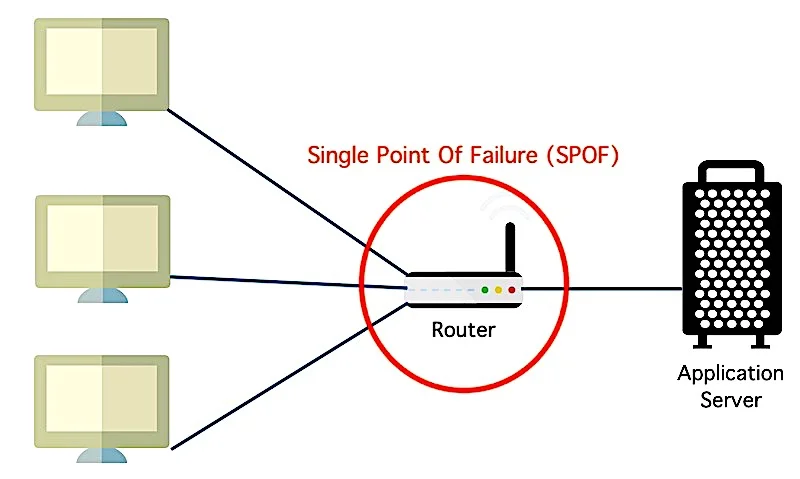
For example, if you are running a website that is hosted on only one server in a particular location, then that server would be a single point of failure. If the server fails, visitors won’t be able to access the website. This single point can bring every activity related to your website to a grinding halt. If such a risk exists in your business, you need to take steps to mitigate that risk.
What’s The Solution?
The most effective way to reduce the potential risk of SPOFs is to add redundancy. This involves installing redundant hardware components and software applications.
For example, one could use Redundant Arrays of Independent Disks (RAID) to store Directory Server databases, or deploy multiple, duplicate instances of Directory Server on different hosts.
Redundancy can be added at different levels. Let’s take the example of an independent taxi driver. At a basic level, he may have tools and spare parts to repair the vehicle if it breaks down. At the medium level, he may borrow his friend’s taxi to do the job. At the highest level, he may have another car and enough components to completely replace faulty parts in the case of multiple failures.
Now, let’s look at a simple example of redundancy in computing.
1.) In a simple setup, there could be several possible single points of failure.
 Figure 1
Figure 1
2.) Some single points of failure can be avoided by adding duplicate hardware components.
 Figure 2
Figure 2
3). Zero SPOF can be achieved by building a fully redundant system, though this setup is way more expensive than the simple setup shown in figure 1.
 Figure 3 | Zero SPOF
Figure 3 | Zero SPOF
At the system level, a load balancer can be deployed to ensure high availability for a cluster of servers. In this case, each server can have multiple hard drives, power supplies, and other modules. A higher level of redundancy can be achieved by adding extra servers that could take on the load of active servers if they fail.
The data center itself supports many operations, like business logic. Therefore, it is in itself a potential SPOF for the business, if its features cannot be replicated elsewhere.
At the site (highest) level, the entire data center can be replicated in different settings and accessed when the primary server becomes unresponsive. This type of redundancy is usually the focus of an IT disaster resiliency or recovery program.
To avoid SPOF, large networks — including the Internet and ARPANET — use packet switching, a technique for routing and transferring data as packets over a digital network. It utilizes multiple paths between two hosts on the network and optimally uses channel capacity.
Read: 10 Organizations That Control The Internet
When there is a fault in any node between the two hosts, the data is transferred through an alternative node. Packet switching also minimizes transmission latency and increases the robustness of communication.
Three network protocols are widely used to prevent a single point of failure:
- Intermediate System to Intermediate System moves information efficiently within a computer network by determining the best route for data.
- Open Shortest Path First distributes routing information between routers belonging to a single autonomous system. It uses the shortest path first (Dijkstra’s) algorithm to transmit data.
- Shortest Path Bridging simplifies the development and configuration of a network while enabling multipath routing.
Assessing SPOF
The three common places where SPOF tend to occur are hardware, software, and third-party services/providers. Humans are also a single point of failure in most organizations, but they are often overlooked. People in a business can be SPOFs for several reasons, such as mistakes, fraud, dishonesty, lack of knowledge, and limited experience.
Once you detect SPOF, the next step is to classify it in terms of how difficult it is to fix it. There could be three categories:
- Easy: Can be fixed within a reasonable time and cost.
- Moderate: Cannot be remediated directly; however, a reliable workaround could be developed.
- Difficult: The fault is tricky and very expensive to remediate.
In addition, SPOFs can be classified by probability of occurrence (low, medium, and high) and by impact on the business (low, medium, and high).
Preventing Single Point of Failure
Since so many mission-critical processes depend on network connectivity, data center outages cannot be tolerated. Still, over 30% of all data centers experience an outage annually. About 34% of businesses say that one hour of downtime costs more than $1 million.
Regardless of losses caused by data center downtime, the reality is that as much as 80% of outages are preventable. While any tool in the network can pose a SPOF hazard, most outages are caused by malware and other cyber threats.
Modern threat protection tools, including load balancers, Intrusion Prevention Systems, web application firewalls, and Advanced Threat Protection solutions, are always at risk during power failures or Network Interface Controller failures, or when filtering internet traffic.
These tools are vulnerable to both ordinary threats, such as brute-force attacks, and complex threats, such as the exploitation of XML external entities or cross-site request forgery. Since they can’t protect the network at all times, it is necessary to implement redundant security measures.
There are several methods to implement web application firewall architecture that minimize the effectiveness and frequency of a broad range of attacks. For instance, multi-tier web app firewalls separate application modules based on their operations into multiple tiers.
Since each tier runs on an individual system, there is no SPOF. In the same way, properly implementing multiple load balancers can reduce the single point of failure within a network.
Do Not Put All Of Your Eggs In One Basket
Although many companies offer their own cloud backup solutions, it is not advisable to rely solely on a single backup to protect your business’s data. Even cloud services from tech giants like Amazon, Microsoft, and Google fail multiple times annually.
If you are running a company, you need to account for all possible scenarios when implementing redundancy. Do not assume anyone can provide a 100% uptime, and always be ready with Plan B if things go wrong.
In-depth Studies
SPOF Within Systems-of-Systems
Researchers at Liverpool John Moores University, UK, highlight major challenges faced when integrating individual systems to form large, complex, heterogeneous Systems-of-Systems.
Many modern approaches tend to focus on a single, specific vulnerable area. Some of them are highly theoretical or unscalable due to a large number of collaborating components. The study describes how a single point of failure can heavily impact collaborating systems and cause significant financial losses for businesses.
Eliminating SPOF in Software-Based Redundancy
Software-based redundancy is usually considered an effective and inexpensive way to enhance reliability. Redundant execution via triple modular redundancy (TMR) is quite popular, but it leaves unprotected SPOFs.
This research presents a holistic approach, named Combined Redundancy, that hardens safety-critical components of a system against soft errors, while eliminating the vulnerability caused by SPOFs. It leverages redundant execution along with encoded processing and can be easily integrated into existing projects.
Minimizing SPOFs In Tree Routing
Tree Routing (TR) utilizes parent-child links to transmit packets. These links require more hops when the source and destination nodes belong to different tree branches. Nodes closer to the coordinator may transmit more packets, leading to higher energy consumption and more congestion. This could create a SPOF problem.
A team of researchers at the National Kaohsiung University of Applied Sciences, Taiwan, has developed a Relieving SPOF Tree Routing algorithm to transmit packets via the shortest path and avoid congestion. The algorithm decreases average hop count, minimizes end-to-end delay, increases throughput, and prolongs the lifetime of tree nodes.
Read More

