Snowflake has become one of the leading tech companies in the cloud-based data management arena. It provides a data storage and analytics service, commonly referred to as Data-as-a-Service (DaaS).
The company offers various tools and innovative features to store and analyze data separately, share data with specific users, clone important data, and handle spikes in demand. Its platform is uniquely built to connect businesses across any type or scale of data and various workloads.
This global platform, which powers the data cloud, runs on the Google Cloud, Microsoft Azure, and Amazon S3 service. In recent years, it has become popular due to its fully managed and cost-efficient cloud-based data solutions.
However, Snowflake faces tough competition from many cloud-leading companies. Most competitors offer a diverse range of services with better features at reasonable prices.
To help you select the best option, we have compiled a list of top Snowflake competitors based on their product offerings, customer bases, and market recognition.
Did you know?
The global cloud data warehouse market size is projected to exceed $155.6 billion by 2034, growing at a CAGR of 17.5%. Growth is primarily driven by the increasing demand for real-time insights and the broader adoption of AI and machine learning.

Table of Contents
14. SAP Datasphere
Released in 2019
Rating: 8.8/10 from 250+ customers
SAP Datasphere (the next generation of SAP Data Warehouse Cloud) is a comprehensive data platform built for mission-critical business data. It features data integration, data federation, data cataloging, data warehousing, and data virtualization.
The platform is integrated with dozens of tools and services that help you organize, manage, and analyze data from different sources. Access all your data across hybrid and cloud environments and find actionable insights — with business context and logic intact.
Key Features
- Self-service access to data products
- Facilitate real-time data access
- In-database machine learning
- Deliver centralized governance, privacy, and compliance
You can create a catalog of analytic assets, key performance metrics, and glossary terms. Connect this catalog to other source systems to bring everything into a single place. The resulting data is controlled by catalog administrators.
It also includes a knowledge graph that maps data relationships such as metadata, lineage, and business context, with a strong focus on SAP application data. This provides a deeper semantic understanding of data, supports AI and LLMs, and helps reduce “hallucinations” by supplying the right context.
Furthermore, the platform can be seamlessly integrated with Microsoft Excel, SAP Analytics Cloud, public OData APIs, and popular AI platforms to capitalize on data investments.
13. Dremio
Unify your analytics and break-down data silos. Dremio makes it easy to federate analytics across Snowflake and all your data to boost performance, deliver lightning-fast, intuitive self-service access for the fastest time-to-insight. Read more here:https://t.co/4vREwUgBRE pic.twitter.com/acQKoDhjTe
— Dremio (@dremio) June 21, 2024
Released in 2015
Rating: 8.7/10 from 150+ customers
Built on open data architecture, Dremio allows you to create and manage a data lakehouse (stored in open formats like Apache Iceberg) and use state-of-the-art data processing engines for various analytics use cases. It accelerates Analytics and Business Intelligence directly on cloud data lake storage.
Its user-friendly SQL query engine features a semantic layer, which allows you to quickly access the data you need, create views, query across different data sources, and update Apache Iceberg tables using data manipulation language (DML).
You can use the built-in SQL Runner to query Lakehouse data. This IDE features multi-statement execution, auto-complete, and the ability to share SQL scripts.
There is an SQL Profiler that helps you understand and optimize query performance. For complex data, you can utilize the built-in Data Map to visualize dataset usage and lineage.
Key Features
- Open data, no lock-on
- Self–service analytics
- Sub-second performance at ten times lower cost
- Built-in governance and lineage
Dremio now supports connections to Iceberg catalogs through the REST API (generic Iceberg REST Catalog). Recent updates also allow writing to Iceberg REST sources, including Snowflake Open Catalog, Unity Catalog, and the generic REST catalog.
Overall, the platform provides best-in-class processing engines while eliminating vendor lock-in. It fulfills the performance and scale requirements of most global enterprises, including five of the Fortune 10.
You can try out Dremio’s selected features for free. This includes querying an Apache Iceberg table stored in Amazon S3, joining data from a Postgres database and Amazon S3, and connecting to Power BI and Tableau to create a dashboard.
12. Panoply
The power of data can’t be overstated. It may seem like enterprises have the upper hand in getting insights, but with the right tools, SMBs can transform their business data into the insights that propel them forward.#data #insights #dataplatform #SMBhttps://t.co/vwNnKobwGf
— Panoply (@panoplyio) May 22, 2024
Released in 2021
Rating: 8.6/10 from 130+ customers
With Panoply, you can easily store and manage data from many applications and streamline data analysis processes. It automatically detects data types and helps you track the status of data sync as ‘scheduled,’ ‘pending,’ or ‘running.’
Key Features
- Connect data from 40+ sources without complicated code
- Auto-detect data types and monitor job status
- User-friendly Workbench for SQL-based data exploration
- Compatible with visualization and BI tools
It is the first unified ETL and Smart Data Warehouse that accelerates the process of migrating raw data to analytics using natural language processing and machine learning techniques.
As for pricing, Panoply offers three plans: Lite ($399 per month), Basic ($1089 per month), and Standard ($1719 per month). The Lite version gives you access to 1 TB of Storage and 50 GiB of Query Bytes. You can try it for free for 21 days.
The platform has experienced rapid growth in the retail and e-commerce sectors. For instance, it reported a nearly 600% year-over-year increase in retail customers, with many online businesses using Panoply to integrate data from platforms like Shopify, Square, PayPal, and NetSuite.
11. StarRocks
Released in 2020
Competitive Edge: Open source; High concurrency & performance
StarRocks is a modern, high-performance distributed analytical database engine designed for real-time OLAP (Online Analytical Processing). It delivers very low-latency, high-concurrency queries on large analytic datasets.
It utilizes a fully vectorized execution engine, which enhances CPU efficiency by processing multiple data elements in a batch using vectorized instructions. Plus, it supports various table schemas (flat tables, star schema, snowflake schema), materialized views, and a cost-based optimizer (CBO), allowing complex multi-table joins to execute efficiently.
StarRocks supports real-time data ingestion at high throughput and also allows updates and deletes in primary key tables. This sets it apart from many traditional data warehouses, which are mostly append-only.
Key performance
- It can ingest streaming data at ~ 100 MB/s per node
- Supports over 10,000 queries per second in high-concurrency scenarios
StarRocks is commonly used as the backend for business intelligence tools, internal dashboards, and interactive analytics in various industries, including advertising, gaming, e-commerce, and telemetry/observability workloads.
The core StarRocks engine is open source under Apache 2.0, allowing enterprises to adopt and experiment freely. It is reportedly used by more than 500 companies, including major names like Airbnb, Lenovo, and Trip.com.
10. Azure Synapse Analytics
Released in 2019
Pricing: $4,700 for 5000 Synapse Commit Units | Free $200 credit to use in 30 days
Rating: 8.5/10 from 200+ customers
Azure Synapse Analytics combines data integration, data warehousing, and big data analytics. The aim is to deliver a unified experience to prepare, explore, manage, and transform data for specific machine learning and Business Intelligence needs.
Users can query data the way they want through either serverless or dedicated options. They can select from multiple programming languages (including Java, Python, .NET, R, Scala, and SQL) to perform queries and gain valuable insights across datasets.
For critical workloads, they can optimize query performance using workload isolation, limitless concurrency, and smart workload management.
Plus, one can easily apply machine learning models to all applications without any data movement. This substantially reduces the development time of large projects.
Key Features
- Code-free hybrid data integration
- Serverless and dedicated options
- Log and telemetry analytics
- Discover regulatory risks and workflow efficiencies across datasets
The platform utilizes advanced security and privacy features, including always-on encryption and automated threat detection, to safeguard customers’ data. It gives users granular control with row-level and column-level security, column-level encryption, and advanced data masking to protect sensitive information in real-time.
As for pricing, Azure Synapse Analytics offers multiple options. The most efficient one is the pay-as-you-go model. Once you create a data warehouse, you are charged hourly for ‘Storage’ and ‘Compute.’ While Storage is usually billed at $23 per TB per month, Compute is billed at $850 per 100 Data Warehouse Units (DWUs) per month.
9. Databricks Lakehouse

Released in 2013
Pricing: Starts at $0.07 per Databricks Unit (DBU) | 14-day free trial available
Rating: 8.3/10 from 100+ customers
Databricks Lakehouse combines all the good characteristics of data lakes and data warehouses to deliver reliable and high-performance cloud solutions. It eliminates the data silos that traditionally complicate the process of machine learning, analytics, and data science.
In other words, it simplifies your modern data stack and puts all features into a single platform. This means you can move data faster without accessing multiple systems. The platform also ensures that you have a comprehensive and up-to-date system available for machine learning, business analytics, and data science projects.
More specifically, the platform is integrated with SQL and performance features (like indexing, caching, and massively parallel processing) to implement Business Intelligence on data lakes. It also offers direct file access and native support for Python, as well as various AI and data science frameworks.
Key Technologies that enable data lakehouse
- Metadata layer for data lakes
- Advanced query engines for SQL execution
- Optimized access for machine learning and data science tools
The pricing varies as per the services you choose and the number of DBUs you use. You can start with a free trial, which provides interactive notebooks for using SQL, Scala, Spark, Python, scikit-learn, Keras, and TensorFlow.
Although Lakehouse is completely free during the trial, you will still be billed by your cloud provider for resources used within your account.
More than 15,000 companies worldwide use Databricks to enable efficient machine learning, large-scale data science, and business analytics.
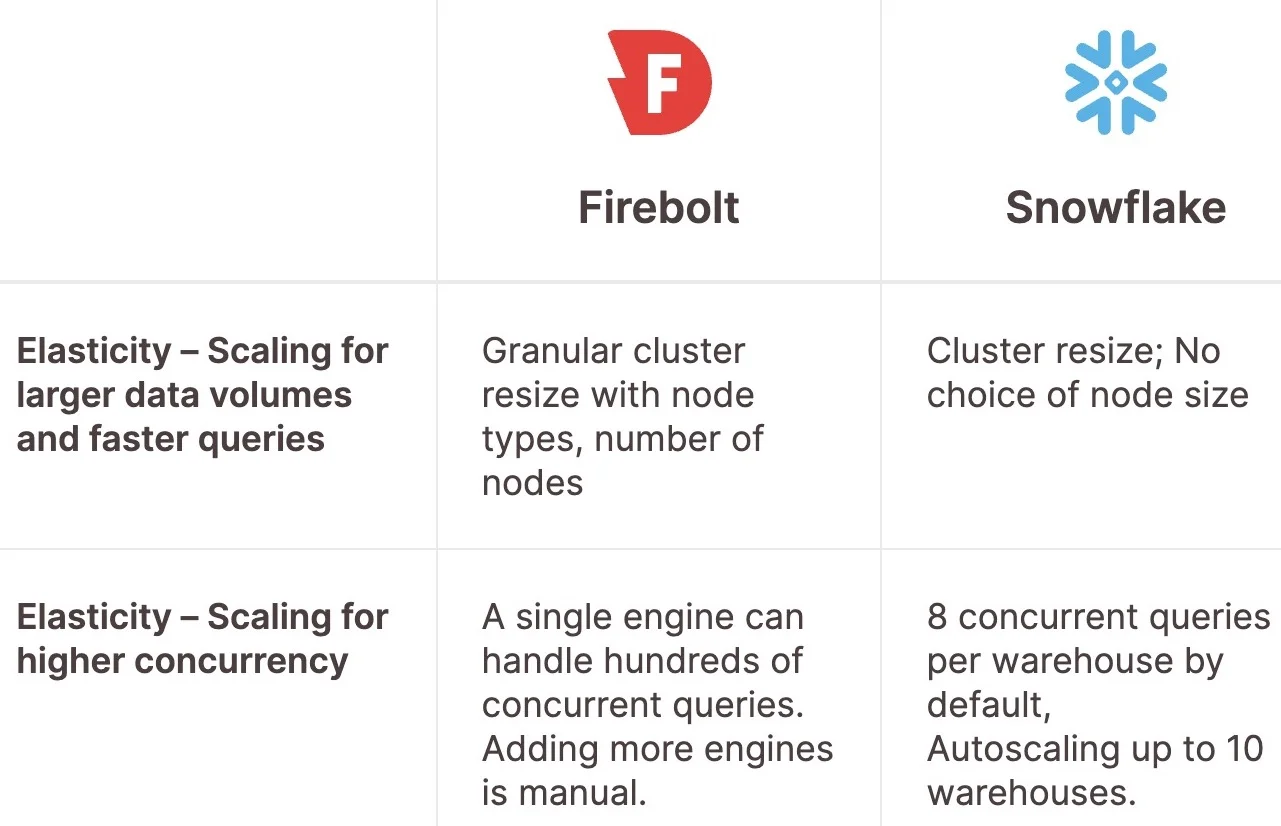
8. Firebolt
Released in 2019
Pricing: Starts at $1 per hour | Free trial available
Rating: 9.3/10 from 200+ customers
With Firebolt’s storage and compute-optimized technology, you can deliver highly concurrent analytics experiences over big data. It is designed to fit into modern data stacks and deliver enterprise-level data applications.
The platform is based on an isolated compute and storage model, which enables linear scalability for both data and compute. In simple terms, it has the capability to scale and decouple computer workloads and users. This ‘decoupling architecture’ eliminates traditional complexities, making it easier to handle data challenges as your business grows.
Key Features
- Granular control over your computing resources and cost
- Vectorized processing and index-based optimization
- Sub-second load times at TB scale
Unlike Snowflake, which doesn’t distinguish between SSD and HDD and stores full partitions in the cache, Firebolt monitors data in both cache and storage and then generates a query strategy to maximize performance.
It’s a multi-tenant SaaS cloud data warehouse that supports REST APIs and ANSI SQL via JDBC drivers.
Getting started with Firebolt is easy — choose from various instance types and cluster sizes, starting from $1 per hour. You don’t have to pay any upfront cost or additional charge (just pay the AWS list price for the data you use).
In 2025, Firebolt introduced FireScale, a benchmark designed for low-latency and high-concurrency analytics workloads. In this test, it achieved a latency of around 120 ms at 2,500 QPS and claimed an 8× better price-performance compared to Snowflake.
7. Oracle Autonomous Data Warehouse
Released in 2018
Pricing: Starts at $0.25 per ECPU per hour | Free version available
Rating: 9.1/10 from 200+ customers
Oracle Autonomous Data Warehouse is optimized for big data analytics workloads, including data lakes, data marts, and data lakehouses. It makes it easier for business analysts and data engineers to discover actionable insights using data of any type and size.
Developed for the cloud and optimized using Oracle Exadata, the platform delivers faster performance at relatively lower operational costs. Its autonomous management functions (like configuration, security, and scaling) eliminate manual tasks and, thus, human errors.
The platform monitors all key metrics related to system performance and automatically fine-tunes itself to deliver consistent performance, even when the number of users, types of queries, and workloads vary over time. To put this into perspective, inserting half a billion rows of data takes, on average, less than three minutes.
Key Features
- Auto-indexing and auto-scaling
- Hybrid columnar compression and columnar processing
- Automated disaster recovery and backups
- Advanced notebooks and visualization
You can utilize a Graph Database to represent complicated data relationships and Graph Analytics to apply classification and statistical analysis for deeper insights.
The free tier allows you to build, test, and deploy instances for an unlimited time. However, it is limited to two Oracle Autonomous Databases, two AMD Compute VMs, and four instances of Ampere Arm A1 Compute. Plus, you get $300 in free credit to try a wide range of Oracle Cloud services.
Oracle has reduced Exadata storage costs by more than 75% in some cases, bringing them closer to object storage pricing while still delivering up to 20 times faster query performance.
For example, POSCO, a leading steel company in Korea, uses Oracle Autonomous Data Warehouse to unify its data lake and warehouse. This has enabled smart manufacturing and improved analytics speed by approximately 2.4 times compared to its previous systems.
6. Druid

Released in 2012
Pricing: Starts at $0.03 per hour | Free trial available
Rating: 8.6/10 from 80+ customers
Druid is an open-source platform that ingests massive amounts of event data and provides low-latency (real-time) queries on top of the data. It facilitates fast data aggregation, Online Analytical Processing (OLAP) queries, and flexible data exploration.
Since each column of the database is compressed and stored separately, Druid only needs to access the columns required for a particular query. The indexes are inverted for string values, allowing fast scan, filtering, and ranking. Data is smartly organized based on time, which makes time-based queries significantly faster than those in conventional databases.
More specifically, the platform pre-fetches the entire data to the compute layer, making almost all queries sub-second. Queries don’t rely on caching algorithms to catch up.
There are two options for performing a query: via Hive SQL or a native REST API.
Key Features
- Injected data is automatically optimized
- Automatically balances servers as users add or remove servers
- Interactive Query Engine
- Fault-tolerant architecture
- Easy to scale up and scale out
- Integrated with Apache Hive and Apache Ambari
The platform supports Kafka and Kinesis, so you can easily ingest real-time data without any connectors. It can query streaming data as soon as it arrives at the cluster, even hundreds of thousands of events per second. You don’t have to wait as the data makes its way to storage.
Overall, Druid is a perfect tool for building real-time analytics apps that consistently support millions of queries per second. Its highly efficient architecture requires less infrastructure compared to other databases.
5. IBM Db2
Released in 1993
Pricing: Starts at $99 per month | Free version available
Rating: 8.2/10 from 1,000+ customers
IBM Db2 provides a single platform for developers, enterprise architects, and database analysts to store, manage, and query data. Regardless of the size or complexity of the data, it enhances the security and performance of applications.
You can easily move data from the Db2 database to a data warehouse for analytics, reduce server power consumption, and optimize IT operations using built-in storage compression and dynamic resource allocation technology.
Key Features
- Deployed as a fully managed service
- Storage management and workload optimization
- On-demand scaling and cost predictability in the cloud
- Always-on security
Database administration and maintenance are quite simple. You can deploy Db2 as a conventional installation on top of cloud-based infrastructure or on-premises infrastructure, gaining control over your Db2 deployment.
The other option is to deploy Db2 as a fully managed service on IBM Cloud. This way, you can take advantage of security patches, continuous feature updates, and on-demand scaling in the cloud.
Irrespective of what option you choose, the platform keeps your data encrypted and masked. The end-to-end security system protects data at rest and in motion, identifies suspicious behaviors, and ensures the privacy of your data.
Db2 is moving toward becoming AI-ready with features like vector types, similarity search, and support for both structured and unstructured embeddings. This matches the broader trend of enterprises seeking to leverage their operational and transactional data, along with semantics, embeddings, and documents, within AI pipelines.
Unlike most other platforms, IBM Db2 offers a free version that provides access to 200 MB of storage and 15 database connections. Plus, you get $200 in free credit after completing the signup process.
4. Amazon Redshift
Released in 2012
Pricing: Starts at $99 per month | $300 in free credit for 90 days
Rating: 8.7/10 from 1,000+ customers
Redshift can efficiently handle analytical workloads on big data stored in a column-oriented database management system. It uses SQL to examine structured and semi-structured data across data lakes, operational databases, and data warehouses.
And since Redshift is integrated with advanced compression and parallel processing techniques, it can process billions of rows simultaneously. It also utilizes AWS hardware and machine learning to deliver optimal price performance at all scales.
Key Features
- Query live data across multiple databases
- Low-latency real-world analytics
- Billions of predictions every week within your data warehouse
- Integrates with Apache Spark and AWS services
You can upload data from popular applications (like Google Analytics, Marketo, Splunk, Facebook Ads, Salesforce, etc.) to Redshift data warehouse in a streamlined manner. Then, combine different datasets and analyze them together to generate valuable insights.
Creating a cluster from the AWS console doesn’t take more than a minute. These clusters are managed by AWS, so you don’t have to worry about conventional database administration tasks such as data backup and data encryption.
As for scalability, Redshift enables users to dynamically request scaling up or down of infrastructure as business requirements change. The serverless version further enhances this with AI-powered dynamic scaling, which analyzes workload patterns such as data volume, query complexity, and concurrency, and then adjusts resources proactively.
Anyone can sign up and start using the platform for just $0.25 per hour with no upfront costs or commitments, and scale to 16 petabytes or more for $1,000 per terabyte per year.
3. Vertica

Released in 2005
Pricing: Free for up to 3 nodes and 1 TB of data | Pay-as-you-go model
Rating: 8.6/10 from 300+ customers
Vertica has a wide range of analytical functions spanning event and time series, geospatial, pattern matching, and in-database machine learning capabilities. You can apply these functions to massive analytical workloads and generate actionable insights.
Create your own data lakehouse that supports streaming data, semi-structured data, and external queries on formats like ORC and Parquet. You can even extend its analytical functionality by using Java, C, C++, R, Python, and SQL.
The platform can be deployed on popular public clouds and on-premises data centers. It runs queries in parallel across numerous instances or nodes, delivering 10-50 times faster results at any scale.
Key Features
- High compression
- Massively parallel processing architecture
- More than 650 built-in analytic functions
- Supports conventional programming interfaces like OLEDB, ODBC, and JDBC
It runs more analytics with fewer hardware resources, reducing your Compute and Storage costs by up to 85%. According to Forrester’s Total Economic Impact (TEI) study, Vertica gives an ROI of 385% over a three-year period. It saves millions of dollars wasted in inefficient data warehouse costs and creates significant value through machine learning-driven productivity and intelligent business insights.
The free version of the platform includes all machine learning capabilities for both hybrid and on-premises deployment. It allows you to utilize up to three nodes and one terabyte of data.
2. Teradata Vantage
Released in 2019
Pricing: Starts at $5 per hour compute and $0.20 per terabyte per hour storage
Rating: 8.5/10 from 1,000+ customers
Teradata Vantage unifies data lakes, data warehouses, analytics, and various data types and sources within your organization (from social media to industrial sensors), giving you a single source of truth. It supports all common data formats and types, including CSV, Parquet, BSON, XML, and JSON.
The platform does everything, so you don’t have to manually reorganize databases, rebuild indexes, repartition data, or configure queries. It has over 150 in-database functions, including 50+ time-series functions, and integrated ModelOps, which makes it easier to operationalize analytics at scale.
For business-specific tasks, you can write code in languages like Python and R to enable highly descriptive and predictive analytics.
Key Features
- Integrates different file systems, data types, and analytic engines
- Advanced SQL Engine with machine learning
- Allocate user costs by department
- Detailed insights by scaling large data in complex models
- Reduces unplanned downtime and failures
The platform can train models on 1 million+ observations and score them against 250 million+ observations several times a day. This is how it scales machine learning vertically.
It can also train millions of predictive models (to support hyper-segmentation use cases) and score them every day in a fast-growing production environment. And this is how it scales horizontally.
In 2024, Teradata announced a collaboration with NVIDIA to integrate NeMo and NIM microservices into the Vantage platform. The goal is to accelerate AI workloads, including foundation and custom large language models (LLMs), support RAG (retrieval-augmented generation) workflows, and enable customers to deploy “bring-your-own” LLMs.
In 2025, the company introduced Teradata AI Factory, a private, on-premises AI solution. It combines Teradata’s AI/ML capabilities, including generative and agent-based AI, with hardware and infrastructure powered by NVIDIA GPUs.
All in all, it unleashes the power of artificial intelligence and machine learning that scales up and down, delivering better results.
1. Google BigQuery

Released in 2010
Pricing: Starts at $5 for 2,000 concurrent slots | Free version available
Rating: 8.9/10 from 900+ customers
BigQuery’s serverless architecture allows you to analyze large volumes of data through SQL queries. It works with all data types, so you can easily extract valuable business insights.
It can ingest streaming data and make it available for query almost instantly — the platform’s Business Intelligence Engine provides sub-second query response time and high concurrency.
View spatial data in different ways, analyze complex datasets, and identify new patterns with support for arbitrary points, lines, and multi-polygons in conventional geospatial data formats.
Comparing it with Snowflake, both perform well under heavy load scenarios. You can run benchmarks using your own datasets, but you will probably find that both tools can handle almost all enterprise workloads with consistent performance.
Key Features
- In-memory analyses provide sub-second query response time
- Real-time with event-driven analysis
- Integrates with Business Intelligence and Data
- Apply tools like charts, pivot tables, and formulas to derive insights
Since BigQuery is developed by Google, it seamlessly integrates with Google Ads and Campaign Manager, providing a 360-degree view of your company. You can utilize Google Analytics and built-in machine learning models to increase your ROI.
Google is presenting BigQuery as an autonomous data-to-AI platform by tightly integrating data warehousing and analytics with generative AI, unstructured data, LLMs, and model inference. The focus is on handling multimodal data (structured and unstructured), supporting open lakehouse formats like Apache Iceberg and BigLake, and ensuring governance is built in.
As for pricing, BigQuery offers two options — flat-rate pricing that charges virtual CPUs and on-demand pricing that charges for the number of petabytes processed for each query. The free tier includes 10 GB storage and 1 TB queries per month.
How big is Snowflake?
In 2020, Snowflake raised $3.4 billion via an initial public offering (IPO). It was one of the largest software IPOs.
Although some may consider Snowflake’s growth a bubble, the company is backed by advanced applications, tools, and services that support its growth. It focuses on product innovation and retention of existing clients, which ultimately gives the company an edge over its competitors.
In July 2020, Snowflake acquired CryptoNumerics for $7.1 million. Since CryptoNumerics allows businesses to create privacy-protected datasets with quantifiable privacy risk, this deal opened new avenues for Snowflake to compete in the privacy-based data market.
In October 2022, Snowflake acquired a 5% stake in OpenAP, an advanced TV advertising firm that enables marketers to target and monitor their campaigns across premium TV publishers and platforms.
Their growth has been phenomenal. In FY 2025, the company generated $4.1 billion in revenue, up 28.37% from the previous year. Its gross profit reached $2.74 billion, reflecting a 26.03% YoY increase.
Snowflake now serves over 12,000 customers. Together, they run more than 5.3 billion data queries on the Data Cloud. Customers manage over 250 petabytes of data and handle more than 515 million data workloads each day.
Who uses Snowflake?
The California Department of Technology, Big Fish Games, Albertsons, Hewlett-Packard, The Travelers Companies, and Cardinal Health are among its largest clients.
By industry, the largest customers come from Professional Services, followed by Retail and Banking & Financial Services. By country, the largest segments are the United States, followed by the United Kingdom and Australia.
How much return should Snowflake customers expect?
According to Forrester’s Total Economic Impact report, Snowflake’s clients can expect a 616% ROI and net benefits of $10.7 million over a three-year period. The other advantages include
- 20% growth in business value from data initiatives
- 66% increase in data engineers’ productivity
- 80,000 hours in freed bandwidth among data teams
Market size of Big Data as a Service Platforms
According to the Fortune Business Insights report, the global Big Data as a Service (BDaaS) market size is expected to exceed $178.8 billion by 2032, growing at a phenomenal CAGR of 23.3%.
The key factors behind this growth include the massive demand for customer analytics & predictive modeling tools, as well as risk reporting & threat management systems. Plus, the proliferation of interactive visualization and AI applications will impact the market’s development.
Why you can trust us?
We thoroughly analyzed over 35 Snowflake competitors and read their customers’ reviews. It took more than 24 hours to do the comprehensive research. Eventually, we decided to shortlist the 14 alternatives based on their machine learning capability, services offered, and pricing model.
Our “Rating” is the average of all ratings given by genuine customers on trusted review sites. In order to show you an accurate picture, we haven’t considered reviews and testimonials featured on the platform’s official website.
We DO NOT earn commission from any of the featured platforms. Moreover, we have two independent editors who have no influence over our listing criteria or recommendations.
Read More

